The Different Layers of AI Innovation →
When we hear about AI applications these days, either companies like NVIDIA or Graphcore is in focus or the companies that develop applications like OpenAI or Meta is in focus. However there are several layers to AI. Understanding what constitutes the different layers and which companies are the key players in any or many of the layers would enable one to identify moats, challenges and growth drivers of such companies. Besides, one could also identify potential for future opportunities for vertical integration and consolidation.
AI had many winters over the last several decades. However, over the last decade AI enabled applications seem to be proliferating and has already been infused with several day to day software applications - like voice assistants, maps, translators, etc. Two key developments that happened over the last couple of decades are chiefly responsible for this proliferation:
- Availability of data, due to inexpensive sensors (image sensors like camera, messages in social media apps, etc.)
- Availability of compute, due to faster CPUs and GPUs
Looking at just the two key components would mislead us to think about just software to process the data and hardware to execute the software. One might want to break it down into further components in order to identify the key players in each of the components.
Layers of AI
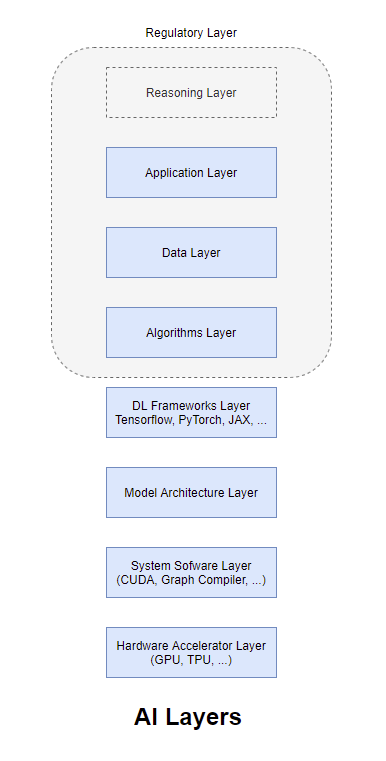
Hardware Accelerator Layer
This is the one of the main layers that brought AI research out of its many winters. Kumar’s work at Microsoft Research, Dan Ciresan’s work at IDSIA on accelerating CNNs (Convolutional Neural Networks) using GPUs followed by the famous AlexNet work brought attention to the use of hardware acclerators like GPUs for applications that are heavy on matrix computations. GPUs are Single Instruction Multiple Data (SIMD) architecture machines that could excel at tasks that are massively parallel. Subsequently, there were other accelerators built based on other architectures like Bulk Synchronous Processing (BSP) (e.g. Graphcore), or Systolic Arrays (e.g. TPUs) that were targeted on accelerating specific architectures. A broad install base as well as accelerators fine tuned over a long period of time to excel at specific deep learning model architectures and deep learning frameworks could serve as a moat that prevents others from having a slice of the market share easily. A good analogy is to think of hardware layer as the muscles that enable heavy computations.
System Software/Compiler Layer
The System Software or Compiler Layer sits closest to the hardware accelerator thereby optimizing the executions of machine instructions as much as possible. CUDA and OpenCL are the programming models closely tied to the software drivers (system software) or compilers. Lately, Graphcore has graph compilers that optimizes the execution of graph networks (using the Poplar SDK) on Graphcore IPUs. There are also companies like Groq that make a much tighter integration between the compiler layer and the hardware layer. In particular, the Groq compiler does all the optimizations on the input model and continuously orchestrates the instructions as operands for those instructions arrive, with the exact knowledge of which hardware execution units are available to execute the instructions.
Model Architecture Layer
It is not often that one can separate out this layer. Once certain model architectures become stabilized, it might make sense to optimize the layers beneath it (hardware and system software layers) in order to serve this particular architecture. The popular architectures might be Transformers for languages, Convolutional Neural Networks for Images, Graph Neural Networks for graph datasets, etc. However, since newer algorithms are still being developed, the current trends are more about optimizing the hardware and system software layers to optimize specific components of the models. The Transformer Engine in H100 GPUs would be an example of such an optimization.
Deep Learning (DL) Frameworks Layer
The different DL Frameworks like Tensorflow, PyTorch, JAX, etc. are similar superficially and have over the years become more similar than different. However, there are compiler instrumentations that optimize such frameworks, very much like Groq Compiler, NVIDIA CUDA, OpenAI Triton, etc. Some of the optimizations like operator fusion have been adopted by the DL frameworks like PyTorch by default and many more such optimizations might become default as research and engineering in DL advances. This layer is also important as it might turn out to be critical to the iterative development of algorithms. Most DL algorithms are iterative in nature and having fine grained control over the progress of the experiments in terms of debugging, performance analysis and the like would ultimately determine the popularity, adoption and subsequently advances in such frameworks. For example, PyTorch executes eagerly using dynamic graphs, it was much easier for programmers to monitor. Tensorflow moved to eager execution from later versions. Which framework is best suited is an ongoing debate in the community with academic researchers leaning towards PyTorch and production engineers leaning towards Tensorflow. There have been other frameworks which were popular initially but lost steam over time.
Algorithms Layer
Algorithmic innovations have led to developments in newer, efficient and more effective model architectures. Though some of the algorithms have been known for a very long time (like backpropagation, CNNs, etc.) the development in other layers (availability of general purpose programmable hardware accelerators, easy-to-use DL frameworks and most importantly the availability of data to train the networks) have significantly aided advancements in algorithms. This has led to architectures like Transformers with layers like Attention that seem to push forward the state-of-the-art in DL research. However, it wasn’t an easy innovation and it is definitely not the last - researchers tried different architectures from Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM), Sequence-to-Sequence models, etc. before iteratively discovering the bottlenecks and devising newer architectures to optimize those. If one of these algorithms were determined to be the most optimal, it would make sense to bake it in silicon in order to get the most efficient performance. It has not happened yet as one does not know what future architectures would bring in this fast paced world of DL research.
Data Layer
There were 5 exabytes of information created between the dawn of civilization through 2003, but that much information is now created every 2 days.” – Eric Schmidt
Data along with Compute is one of the key drivers of today’s Deep Learning advances. The growth and availability of inexpensive sensors and access to analyze them has put all the algorithms that were developed in theory over the past several decades into practice within a span of a decade. However, as DL applications impermeate more and more of our lives, there would be questions around the source of data the models were trained on and if the data provider was compensated for the same. Further, the emergent behaviors of today’s AI systems are the result of the data they were trained on but without having the ability to trace back the emergent behavior to the data points that led to it. These would be the areas of research that could eventually lead to explainable AI systems that we aspire for.
Reasoning Layer
Different from logical reasoning systems which were referred to as reasoning engines, today’s AI systems are more analogy engines than reasoning ones. The exceptional efficiency and effectiveness of such systems seem to be the result of emergent behavior arising from training these systems on unbelievably vast quantities of data. Even with its effectiveness in language tasks, such AI systems seem to be not so good at logical reasoning. The infusion of logical reasoning behaviors into analogy based reasoning architectures of today’s systems would possibly create effective systems that is also able to reason about its emergent behaviors. Since the research in this area is not very well developed at the time of this writing, it is depicted as a grey box in the image above.
Regulatory Layer
This layer is still an underdeveloped layer (and hence depicted using dotted lines). With recent discussions around the data the systems are trained on and the transparency of algorithms and their explainability, this layer might encompass more than just the data layer and the algorithms layer. In the coming years the systems are likely to get regulated in order to deter inappropriate usage of such systems.
It is indeed a great time for AI - the recent advances in research, several applications and multitude of challenges will make the next few years something exciting to look forward to.