Taking a Random Walk on a Frozen Lake →
In a previous post we played with OpenAI Gym on a simple example so that we can also manually workout and understand what is happening. Further the environment space, rewards, transition dynamics and transition probabilities were all clear (hopefully) from the simple example.
The end goal in Reinforcement Learning (RL) is to program our agent so that they interact with the environment and take decisions on their own and get better at reaching their goal on their own. When we say better we need to also mention what does better mean. It depends on the problem. For the 4x4 FrozenLake example we played with a better agent is one who can reach the G tile in shortest number of steps without falling into H. The policy that gives the best is the optimal policy.
What if we take random steps - at every time step, the agent can roll a die and decide which way to move - how many steps does that take to reach the goal (if at all it can be reached). We know that policy is a distribution of actions over states. We can initialize a policy rand_policy
rand_policy = np.ones([env.observation_space.n, env.action_space.n])
where env.observation_space.n and env.action_space.n are the state spaces of observations and actions (16 and 4 for this example). We can write a simple function that would take a random step sampled from among the possible actions in the action space.
env.step(env.action_space.sample())
We maintain a counter and increment it until the goal state us reached or we fall into a hole, indicating the number of steps until an episode.
def rand_policy_eval():
state = env.reset()
cntr = 0
done = False
while not done:
state, reward, done, info = env.step(env.action_space.sample())
cntr += 1
return cntr
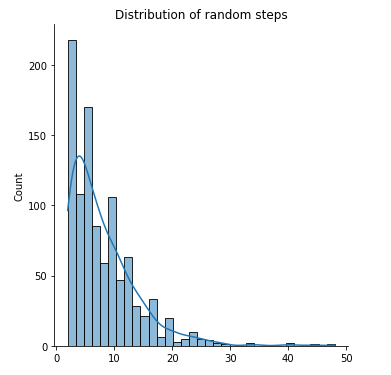
We can plot and see how many steps an episode takes on an average.
rand_steps = [rand_policy_eval() for i in range(1000)]
print(f"Average number of steps to finish episode {np.mean(rand_steps)}")
sns.displot(rand_steps, kde=True)
plt.title('Distribution of random steps')
Average number of steps to finish episode 7.984