-
The Different Layers of AI Innovation →
When we hear about AI applications these days, either companies like NVIDIA or Graphcore is in focus or the companies that develop applications like OpenAI or Meta is in focus. However there are several layers to AI. Understanding what constitutes the different layers and which companies are the key players in any or many of the layers would enable one to identify moats, challenges and growth drivers of such companies. Besides, one could also identify potential for future opportunities for vertical integration and consolidation.
AI had many winters over the last several decades. However, over the last decade AI enabled applications seem to be proliferating and has already been infused with several day to day software applications - like voice assistants, maps, translators, etc. Two key developments that happened over the last couple of decades are chiefly responsible for this proliferation:
- Availability of data, due to inexpensive sensors (image sensors like camera, messages in social media apps, etc.)
- Availability of compute, due to faster CPUs and GPUs
Looking at just the two key components would mislead us to think about just software to process the data and hardware to execute the software. One might want to break it down into further components in order to identify the key players in each of the components.
Layers of AI
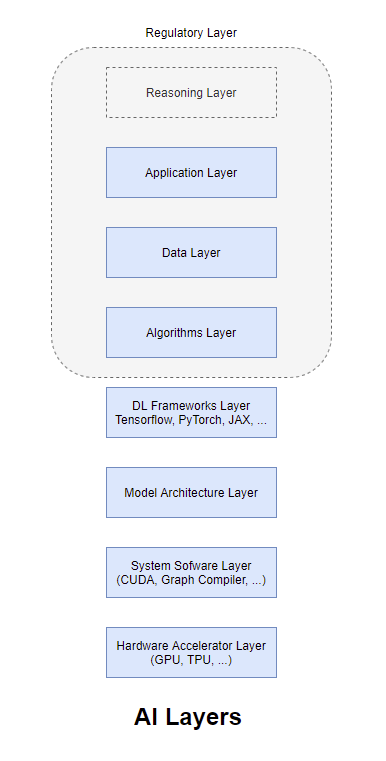
Hardware Accelerator Layer
This is the one of the main layers that brought AI research out of its many winters. Kumar’s work at Microsoft Research, Dan Ciresan’s work at IDSIA on accelerating CNNs (Convolutional Neural Networks) using GPUs followed by the famous AlexNet work brought attention to the use of hardware acclerators like GPUs for applications that are heavy on matrix computations. GPUs are Single Instruction Multiple Data (SIMD) architecture machines that could excel at tasks that are massively parallel. Subsequently, there were other accelerators built based on other architectures like Bulk Synchronous Processing (BSP) (e.g. Graphcore), or Systolic Arrays (e.g. TPUs) that were targeted on accelerating specific architectures. A broad install base as well as accelerators fine tuned over a long period of time to excel at specific deep learning model architectures and deep learning frameworks could serve as a moat that prevents others from having a slice of the market share easily. A good analogy is to think of hardware layer as the muscles that enable heavy computations.
System Software/Compiler Layer
The System Software or Compiler Layer sits closest to the hardware accelerator thereby optimizing the executions of machine instructions as much as possible. CUDA and OpenCL are the programming models closely tied to the software drivers (system software) or compilers. Lately, Graphcore has graph compilers that optimizes the execution of graph networks (using the Poplar SDK) on Graphcore IPUs. There are also companies like Groq that make a much tighter integration between the compiler layer and the hardware layer. In particular, the Groq compiler does all the optimizations on the input model and continuously orchestrates the instructions as operands for those instructions arrive, with the exact knowledge of which hardware execution units are available to execute the instructions.
Model Architecture Layer
It is not often that one can separate out this layer. Once certain model architectures become stabilized, it might make sense to optimize the layers beneath it (hardware and system software layers) in order to serve this particular architecture. The popular architectures might be Transformers for languages, Convolutional Neural Networks for Images, Graph Neural Networks for graph datasets, etc. However, since newer algorithms are still being developed, the current trends are more about optimizing the hardware and system software layers to optimize specific components of the models. The Transformer Engine in H100 GPUs would be an example of such an optimization.
Deep Learning (DL) Frameworks Layer
The different DL Frameworks like Tensorflow, PyTorch, JAX, etc. are similar superficially and have over the years become more similar than different. However, there are compiler instrumentations that optimize such frameworks, very much like Groq Compiler, NVIDIA CUDA, OpenAI Triton, etc. Some of the optimizations like operator fusion have been adopted by the DL frameworks like PyTorch by default and many more such optimizations might become default as research and engineering in DL advances. This layer is also important as it might turn out to be critical to the iterative development of algorithms. Most DL algorithms are iterative in nature and having fine grained control over the progress of the experiments in terms of debugging, performance analysis and the like would ultimately determine the popularity, adoption and subsequently advances in such frameworks. For example, PyTorch executes eagerly using dynamic graphs, it was much easier for programmers to monitor. Tensorflow moved to eager execution from later versions. Which framework is best suited is an ongoing debate in the community with academic researchers leaning towards PyTorch and production engineers leaning towards Tensorflow. There have been other frameworks which were popular initially but lost steam over time.
Algorithms Layer
Algorithmic innovations have led to developments in newer, efficient and more effective model architectures. Though some of the algorithms have been known for a very long time (like backpropagation, CNNs, etc.) the development in other layers (availability of general purpose programmable hardware accelerators, easy-to-use DL frameworks and most importantly the availability of data to train the networks) have significantly aided advancements in algorithms. This has led to architectures like Transformers with layers like Attention that seem to push forward the state-of-the-art in DL research. However, it wasn’t an easy innovation and it is definitely not the last - researchers tried different architectures from Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM), Sequence-to-Sequence models, etc. before iteratively discovering the bottlenecks and devising newer architectures to optimize those. If one of these algorithms were determined to be the most optimal, it would make sense to bake it in silicon in order to get the most efficient performance. It has not happened yet as one does not know what future architectures would bring in this fast paced world of DL research.
Data Layer
There were 5 exabytes of information created between the dawn of civilization through 2003, but that much information is now created every 2 days.” – Eric Schmidt
Data along with Compute is one of the key drivers of today’s Deep Learning advances. The growth and availability of inexpensive sensors and access to analyze them has put all the algorithms that were developed in theory over the past several decades into practice within a span of a decade. However, as DL applications impermeate more and more of our lives, there would be questions around the source of data the models were trained on and if the data provider was compensated for the same. Further, the emergent behaviors of today’s AI systems are the result of the data they were trained on but without having the ability to trace back the emergent behavior to the data points that led to it. These would be the areas of research that could eventually lead to explainable AI systems that we aspire for.
Reasoning Layer
Different from logical reasoning systems which were referred to as reasoning engines, today’s AI systems are more analogy engines than reasoning ones. The exceptional efficiency and effectiveness of such systems seem to be the result of emergent behavior arising from training these systems on unbelievably vast quantities of data. Even with its effectiveness in language tasks, such AI systems seem to be not so good at logical reasoning. The infusion of logical reasoning behaviors into analogy based reasoning architectures of today’s systems would possibly create effective systems that is also able to reason about its emergent behaviors. Since the research in this area is not very well developed at the time of this writing, it is depicted as a grey box in the image above.
Regulatory Layer
This layer is still an underdeveloped layer (and hence depicted using dotted lines). With recent discussions around the data the systems are trained on and the transparency of algorithms and their explainability, this layer might encompass more than just the data layer and the algorithms layer. In the coming years the systems are likely to get regulated in order to deter inappropriate usage of such systems.
It is indeed a great time for AI - the recent advances in research, several applications and multitude of challenges will make the next few years something exciting to look forward to.
-
Logic, Languages and Reasoning →
Human languages developed and evolved over thousands of years. Though most languages have a structure (defined by the rules of grammar) we think of spoken languages as a series of informal statements (“informal” compared to the “formal” rigor of mathematical statements). While informal statements helped human species to communicate and collaborate, eventually evolving languages themselves, informal statements were not enough for settling arguments, legal disputes or discovering (new) knowledge from existing knowledge. Socrates, Plato’s teacher, is credited with coming up with inductive arguments and universal definitions. Aristotle’s logic consisted of formulating statements and deriving new knowledge (conclusion) from the knowledge contained in a set of statements (premises) guided by rules that he called syllogisms. Aristotle, a student of Plato, is credited with the earliest study of logic, formal logic, in his collected works Organon. Plato also contributed to the study of reasoning. While Plato relied on deduction from a priori knowledge and postulated that knowledge of things that happen can be deduced from the knowledge of universal ideas, Aristotle’s epistemology postulated that knowledge of things that happen build up to universal knowledge collectively. Together the main recipes for reasoning - induction, deduction and abduction - were discovered that are the pillars for making reasoning infallible.
Mathematicians developed it further for mathematical reasoning which got shaped, like many mathematical computations, into automated reasoning using computer programs by computer scientists. Mathematical logic is the cornerstone of systems that are used for reasoning about the correctness of computer programs.
We can use NLTK’s Python API to play with it to see what it means to encode English sentences as logical formulas. Once we are able to encode knowledge (in English sentences) we can use well formed rules of logic to deduce new information, also called logical inference.
import nltk from nltk import load_parser grammar_file = 'file:///nltk_data/grammars/book_grammars/simple-sem.fcfg' lp = load_parser(grammar_file) stmt = 'Angus gives a bone to every dog' trees = lp.parse(stmt.split()) for tree in trees: print(tree.label()['SEM'])This gives the semantics in the form of a logical formula:
all z2.(dog(z2) -> exists z1.(bone(z1) & give(angus,z1,z2)))Further more, one could use the theorem prover that comes along with NLTK to check for consistency among statements and prove goals (conclusion) given a list of statements (premises). For example, one could write
mini_has_ball = read_expr('has(mini)') mini2jane = read_expr('pass(mini, jane)') rules = read_expr('all x. all y. (pass(x, y) -> has(y))')We just encoded some English statements as well as the assumption that if x passes the ball to y, then y will have the ball. We can use a theorem prover to prove a goal that jane has the ball and check if it follows from our assumptions, i.e. of the goal can be derived given the assumptions
jane_has_ball = read_expr('has(jane)') prover = nltk.Prover9() prover.prove(jane_has_ball, [rules, mini2jane])and the prover, if it can establish a proof, will return:
TrueThis kind of encoding and logical reasoning might be needed to answer questions like the last one we saw in a previous post. One might also need more expressive logics in order to encode statements about temporal events succinctly. However, languages themselves are stochastic systems which would imply that we would never be able to come up with logically accurate formulations of the sentences we use in everyday conversations, especially when it involves conversations involving languages that are not one’s native language and might have grammatical mistakes and still convey the intended message. Legal documents or financial documents, for example, could be structured in a precise format that might allow one to formulate the sentences in a logical language and make queries that can return an accurate answer that can be reasoned about if needed - think of a healthcare database to which policy makers submit queries in a natural language. A deep learning based approach, which looks at several usage patterns, to arrive at an approximate formulation which would still enable one to deduce new information from a set of facts already provided. This would be more crucial in developing (explainable) AI systems that can be reasoned about, which is especially crucial in healthcare and other critical domains where AI systems are beginning to find their place.
 Death of Socrates, by Jacques Louis David (Credits: The Met)
Death of Socrates, by Jacques Louis David (Credits: The Met) -
Languages, Logic and Computation →
A previous post spoke about state-of-the-art NLP systems that are based on Transformers and some of the challenges around using such systems for translations. Although they could translate almost accurately, they may not match the nuances of spoken (informal) languages. There are other challenges around Question Answering systems - another tasks such NLP systems are capable of doing. In this post, this is explored futher to see when some computation (as in logical inference rather than mathematical inference) is needed to come up with an answer. We play with OpenAI APIs to see how the state-of-the-art NLP systems excel at language understanding and also where they have gaps to fill.
English, like many other languages, is a little ambiguous. There are well established rules of English grammar but I believe there are several statements in common parlance that have introduce some ambiguity. While I tried OpenAI, in particular the
text-davinci-002engine on a variety of English statements and the results were astounding, when I kept going on, there were some statements where the answer was not exactly clear.One of the was what she refers to in a statement like Anna hit Clara because she was drunk. Though it looks ambiguous I believe as Anna is the subject, the she in the statement must refer to Anna. OpenAI does seem to tell me that the she in the statement refers to Anna.
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="Anna hit Clara because she was drunk.\n\nQ: Who was drunk?\nA:", top_p=1, ... ) >>> print(response) { "choices": [ { ... "text": " Anna was drunk." } ], ... }If I rephrase the above statement as Anna hit Clara because she was drunk. Was Clara drunk?, OpenAI was humble enough to admit that it does not know, which is impressive as there isn’t enough context to infer if Clara was drunk.
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="Anna hit Clara because she was drunk.\n\nQ: Was Clara drunk?\nA:", ... stop=["\n"] ) >>> print(response) { "choices": [ { ... "text": " I don't know." } ], ... }What impressed me the most was the ability to do formulaic calculations and return an answer.
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="The sale price of a decent house in California is about a million dollars. 20% of the price needs to be paid as down payment. In addition, the county levies a property tax of 1.2% on the sale price of the house. John takes a 30 year fixed rate mortgage at 3.5% interest rate.\n\nQ: What would be John's monthly cost of ownership? \nA:", ... ) >>> print(response) { "choices": [ { ... "text": " John's monthly cost of ownership would be $4,167." } ], ... }While the ability to solve when numerical information was provided was too impressive, there was some struggle when the answer involved logical interpretation and numerical computation. For example, the query in the following requires interpreting what “boundary” is and how it contributes to the answer.
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="Dhoni scored a single off the first ball of the 11th over. Sachin scored two consecutive boundaries followed by a single. Dhoni hit the biggest six of the match. He then followed it up with a single and retained strike. \n\nQ: How many runs were scored off the 11th over? \nA:", ... ) >>> print(response) { "choices": [ { ... "text": " 15" } ], ... }Human languages are such that they involve logical interpretation, deduction and computation. It is precisely this challenge that leads to misinterpretation, miscommunication and chaos - you can think of the last time a celebrity or a politican claimed his comments were misinterpreted or taken out of context. However, we as human beings deal with these every day and are attuned to the fallacies and inaccuracies. Our communication system, the one that distinguishes us from many other species, is itself a stochastic one.
Some statements require logical deduction which is challenging for deep learning systems (that learn from patterns contained in a training corpus). For example,
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="marco passed the ball to miel, miel quickly gave it to don who passed it on to sky. sky ran with it for a while and gave it to anna.\n\nQ: Does marco have the ball now?\nA:", ... ) >>> print(response) { "choices": [ { ... "text": " No" } ], ... }While the system is able to deduce that marco does not have the ball, a deduction performed to answer who has the ball? doesn’t seem to work well.
>>> response = openai.Completion.create( engine="text-davinci-002", prompt="marco passed the ball to miel, miel quickly gave it to don who passed it on to sky. sky ran with it for a while and gave it to anna.\n\nQ: Who has the ball now?\nA:", ... ) >>> print(response) { "choices": [ { ... "text": "" } ], ... }There is immense research interest in this area and the progress being made is as impressive as that has been achieved so far. Hopefully, in a future post, I will be able to show an NLP system that combines logical reasoning with deep learning and is able to answer much more fancier questions. I am looking forward to it.
-
Languages, Culture and Communication →
Languages have always played a very important role in society and in our cultural evolutions. It has been the vehicle that allowed human beings to collaborate, coexist and achieve great things as well as to deceive, conspire and destroy. Languages have also evolved over time carrying with them many cultural norms, shades of history while also losing some. The same language might sound differently across an ocean or even across geographic land boundaries. Some languages like Sanskrit, though less ambiguous and more efficient, are struggling to survive while others like English are flourishing despite being more ambiguous. In the age of AI based natural language processing (NLP) is it possible to encode some of these norms and cultural connotations in order to make automated translations more close to native spoken languages?
NLP systems are a commonplace today, mostly in the form of personal assistants like Alexa and chatbots like a customer service system. While they are able to understand and respond to usual queries or translate text to a surprising level of accuracy, they are far from matching human levels of communication. My claim is that NLP research is yet to discover the means to encode the several cultural connotations that come with languages, especially while translating from one to another. While NLP algorithms like LSTM and Transformers implicitly encode some of the context needed for better understanding of a statement, a pair of languages might be too different to capture all the context implicitly. Is capturing all of the context necessary? May not be. However, capturing important nuances might be.
I have been playing around with the Hugging Face API for quite sometime and really enjoying the easeness of use - ability to work with different popular transformer models for different types of NLP tasks. And of course, the ability to use several different famous models makes the result almost unbelievable. The
pipeline()- fundamental component in the Transformers library serves as a pipeline between the different steps in an NLP pipeline. For example, we may want to connect a preprocessing step to an analysis step and then to a post-processing step. I believe the ease of use and the availability of several models makes Hugging Face the go-to tool for NLP.from transformers import pipelineWhen instantiating, the
pipeline()expects the user to provide the NLP task we are interested in performing as well as an optional model (when not provided, a default model is used).We can create, for example, a sentiment analyzer by providing
sentiment-analysisas the task. If we do not specify a model to be used, it defaults to Distilbert model.sanalyzer = pipeline('sentiment-analysis')We can pass strings that we want to analyze the sentiment for.
sanalyzer("I plan to learn")and it returns the sentiment and a score of the sentiment.
> [{'label': 'POSITIVE', 'score': 0.9988747239112854}]So “learn” seems to be a positive thing to do. Let’s keep going with this:
sanalyzer("I plan to learn Spanish") > [{'label': 'POSITIVE', 'score': 0.9941837191581726}]So, learning Spanish also seems to be a positive thing to do. However,
sanalyzer("I plan to learn some more Spanish.") > [{'label': 'NEGATIVE', 'score': 0.9369450807571411}]I am not sure why, but learning some more seems to have a negative connotation (may be “some more” indicates some lacking that one is trying to improve upon?). However, if I add an additional phrase the overall sentiment seems to become positive.
sanalyzer("I plan to learn some more Spanish. I want to be able to live and work in Spain.") > [{'label': 'POSITIVE', 'score': 0.9970537424087524}]These are just some of the challenges with current NLP systems. The result could be interpreted in several ways and if the training (of which a model is a result of) was done on specific set of (data from a specific culture or a communication pattern), some phrases might get inferred as
NEGATIVEthough it would not seem negative to the user of such systems. Another example showing a subtle difference:sanalyzer("I plan to learn enough Corporate Finance in order to get a great job") > [{'label': 'NEGATIVE', 'score': 0.5767139792442322}]returns a
NEGATIVEsentiment whilesanalyzer("I plan to learn Corporate Finance in order to get a great job") > [{'label': 'POSITIVE', 'score': 0.902138888835907}]returns a
POSITIVEone:More intriguing are the expressions that we use depending on cultures and traditions. In many languages, we use different pronouns and verb conjugations depending on if we are talking to elders using a formal language or talking to friends or children (informal language) - like vous vs tu in French, aap vs tum in Hindi, avar vs avan in Tamil, iyaal vs ival in Malayalam, etc. Humans have learnt to make that judgement call even when we talk over the phone - we choose formal or informal language depending on how much respect or importance we attach to the person we are talking to, even if it is a stranger and we are speaking to them for the first time. However, NLP systems do not have that context explicitly encoded and it is difficult to implicitly encode them as some languages do not have such differences and while translating from such languages, one would have to possibly over-correct.
en_fr_translator = pipeline("translation_en_to_fr") en_fr_translator("Would you like some coffee?") > [{'translation_text': 'Avez-vous envie de prendre du café ?'}]As we see, we could offer coffee to a close friend (informal language) or we could be a barista offering coffee to a stranger or a customer (using formal language). These are very difficult to encode implicitly. Even when there are some clues in the statement, like the following sentence which talks about balloons which most likely only children would be interested in, most systems would prefer a formal language in order to be absolutely correct.
en_fr_translator("Do you want a balloon?") > [{'translation_text': 'Voulez-vous un ballon?'}]There are also everyday language (colloquial) that differs from a more grammatically correct business or literary language. At times, the differences between the two is so large that chatbots may sound weird. Let us contrast English-French translation with French-English translation to check this.
en_fr_translator("There's no one here.") > [{'translation_text': "Il n'y a personne ici."}]In spoken French, one usually leaves out the negation (ne) in certain cases and so “Il y a personne ici.” would also actually mean “There’s no one here.”
fr_en_translator("Il y a personne ici.") > [{'translation_text': "There's no one here."}]Another example, which might sound very counter-intuitive for people new to the French language.
en_fr_translator("I have") > [{'translation_text': "J'ai"}] en_fr_translator("more bread.") > [{'translation_text': 'plus de pain.'}]Such statements are not always compositional.
fr_en_translator("J'ai plus de pain.") > [{'translation_text': "I don't have any more bread."}]Many NLP systems are trained on formal and informal phrases and hence would be great translators, they may not always be a great teacher. The fluidity of languages makes languages evolve, creating new words, phrases, letting go some rules of grammar and these are exactly what make languages beatiful and a treasure trove for linguists. These are also the same challenges that make NLP a fascinating subject for Computer Scientists. I am eagerly looking forward to understanding the research in this area hoping that there would be some architecture that would enable us encode some of these connotations implicitly, making NLP systems crawl a little closer towards human-like spoken languages.
-
The Year in Formula One →
If you are someone who has been watching Formula One over the last decade, it would be safe to bet that you agree 2021 has been one of the exciting year in the sport. Lots of uncertainity, lots of controversies, new, young and energetic racers, and a super-busy calendar with 22 races. In this post, we will look at the last decade in the sport while doing so using Python and Pandas to analyze, plot and visualize the data.
import pandas as pd constr_df = pd.read_csv('driver_standings_2010_2021.csv') driver_df = pd.read_csv('f1_2010_2021.csv')If we look at the total points by different teams:
team_totals = pd.DataFrame(constr_df.groupby(['team'])['points'] .sum() .sort_values(ascending=False)) .reset_index() sns.barplot(x='team', y='points', data=team_totals) ...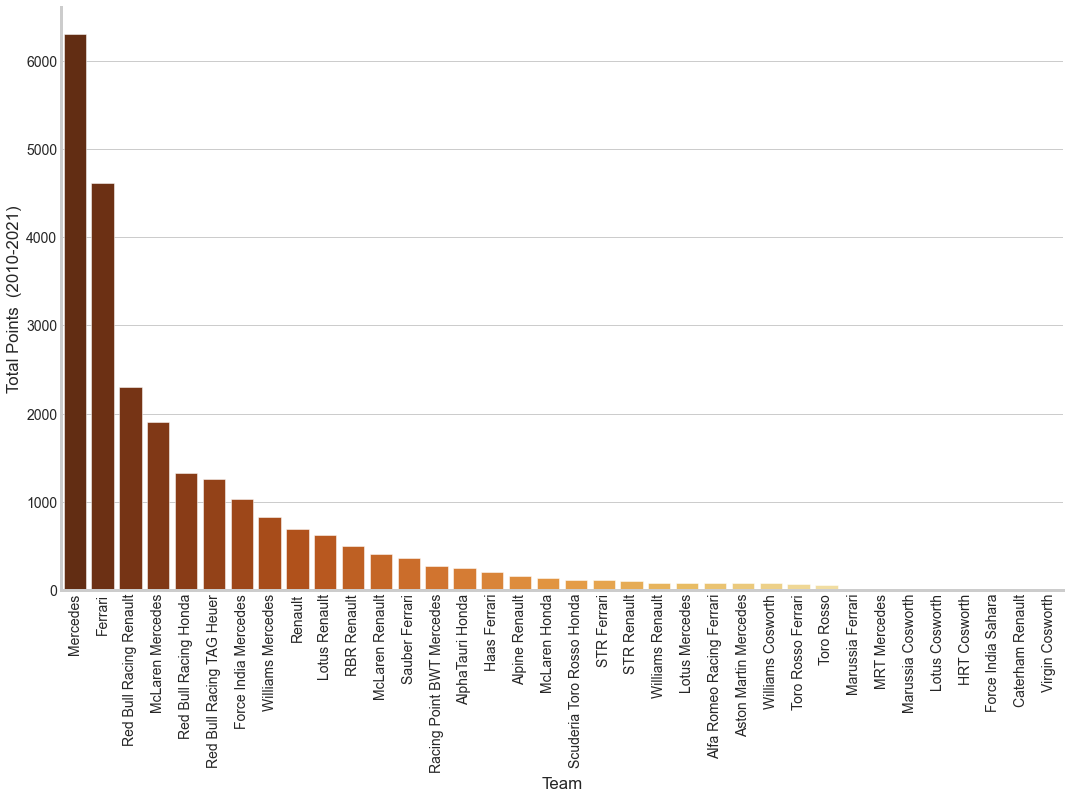
Mercedes is clearly the front runner, most of it contributed by Lewis Hamilton as we will see very soon. Having lived in Italy and a Ferrari Fan, it is sad to see Ferrari in second place and even more sad to see the downward trend for the prancing horse.
Let’s turn to the drivers who play a key role in making the sport what it is. After Mike Schumacher’s retirement, there was some competition between Sebastian Vettel and Lewis Hamilton and to some extent Fernando Alonso and Nico Rosberg. Unfortunately Sebastian Vettel’s dominance faded away and Lewis Hamilton started dominating every race. Very soon there was a new kid in the block - Max Verstappen. Young, energetic and impatient, Max Verstappen, racing for RedBull, quickly started dominating the sport throwing a big challenge to Lewis Hamilton. Many predicted his dominance given the last couple of years and if there was even the slightest of doubts, the 2021 racing season would have cleared those away. Just before the last race, Lewis Hamilton and Max Verstappen were tied on the same number of points which shows the sheer scale of the competition.
driver_totals = pd.DataFrame(driver_df.groupby(['full_name'])['points'] .sum() .sort_values(ascending=False)) .reset_index() sns.barplot(x='full_name', y='points', data=driver_totals) ...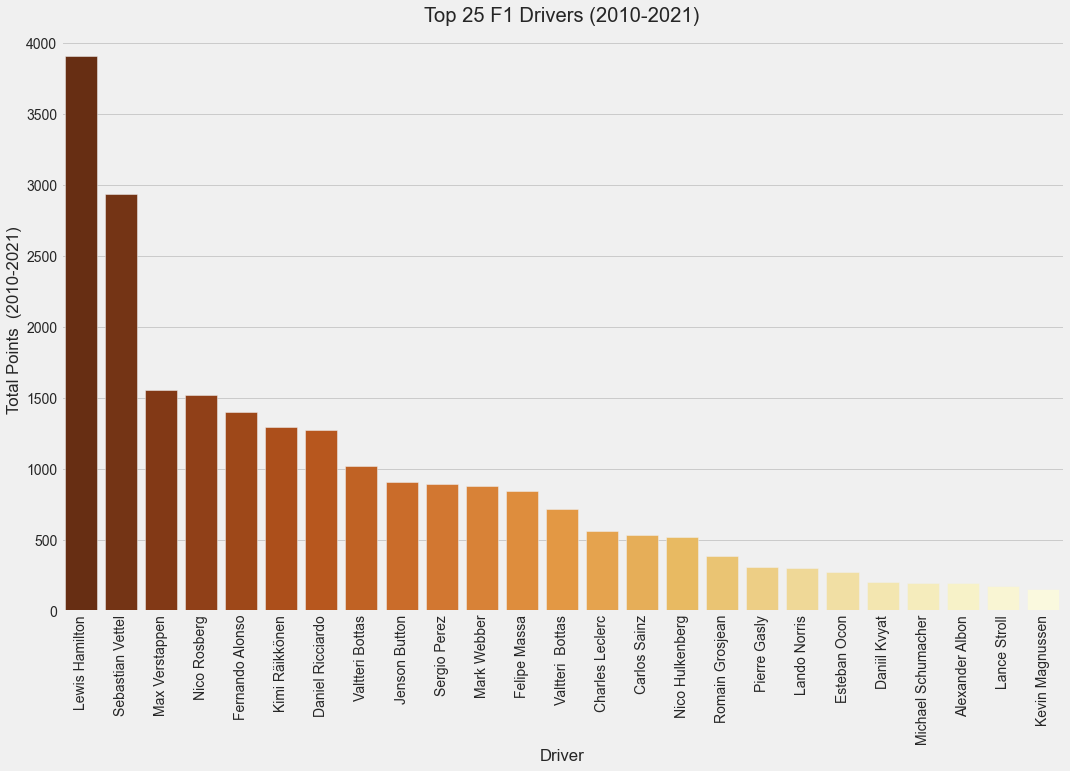
We can also see the maximum points scored by the drivers in any year. This shows Lewis Hamilton dominating the races that were once dominated by Sebastian Vettel.
max_pt_drivers = pd.DataFrame(driver_df[driver_df.groupby(['year'])['points'] .transform('max') == driver_df['points']]) ax = sns.barplot(x='year', y='points', data=max_pt_drivers, palette='crest') for p, (i, txt) in zip(ax.patches, enumerate(max_pt_drivers['name'])): ax.annotate(txt, xy=(p.get_x() + p.get_width() / 2, p.get_height()), xytext=(0, 8), textcoords='offset points', ha='center', va='center', size=12 ) ax.set_xticklabels(ax.get_xticklabels(), rotation=90, fontsize=14); ...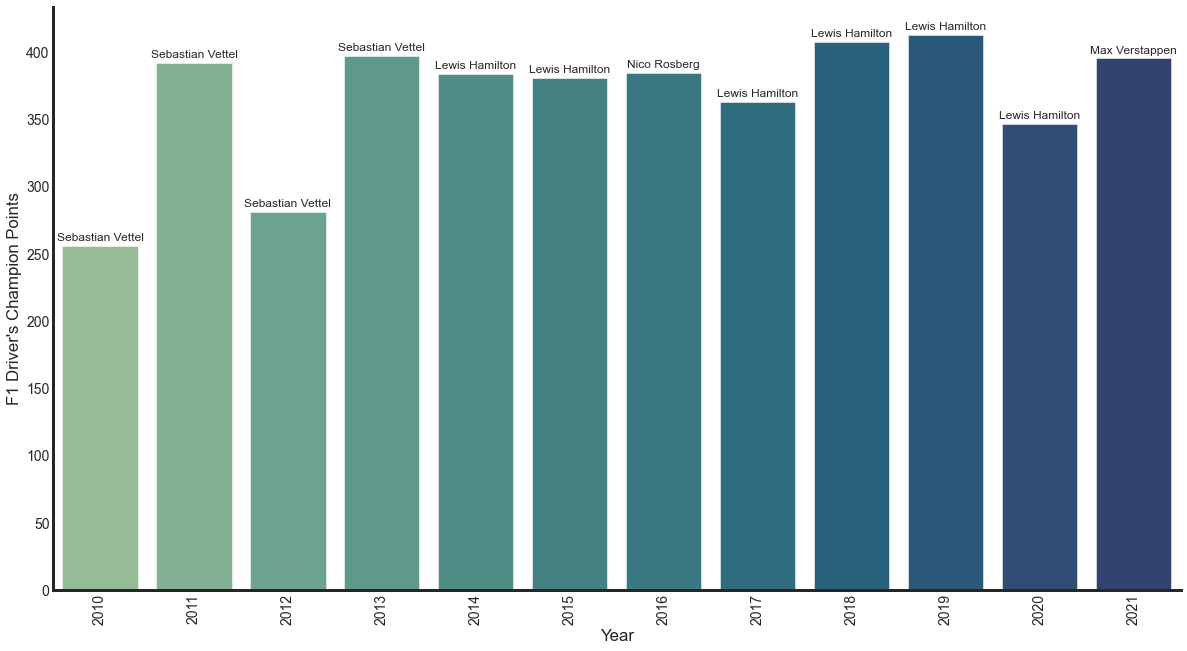
We can also see which countries have scored the most points. Traditionally, Formula One has been more popular in Europe than the rest of the world. There are and were South American champions but not many of them. I believe this might be due to the cost involved in the sport and few can afford it. Further most of the best automobile makers are from Europe (and few from Japan as well). We can attempt to draw a tree map using
squarifyin Python.import squarify country_wins = pd.DataFrame(driver_df.groupby(['nationality'])['points'] .sum() .sort_values(ascending=False)) .reset_index() squarify.plot(sizes=country_wins['points'][:21], label=country_wins['nationality'][:21], alpha=0.8) plt.axis('off')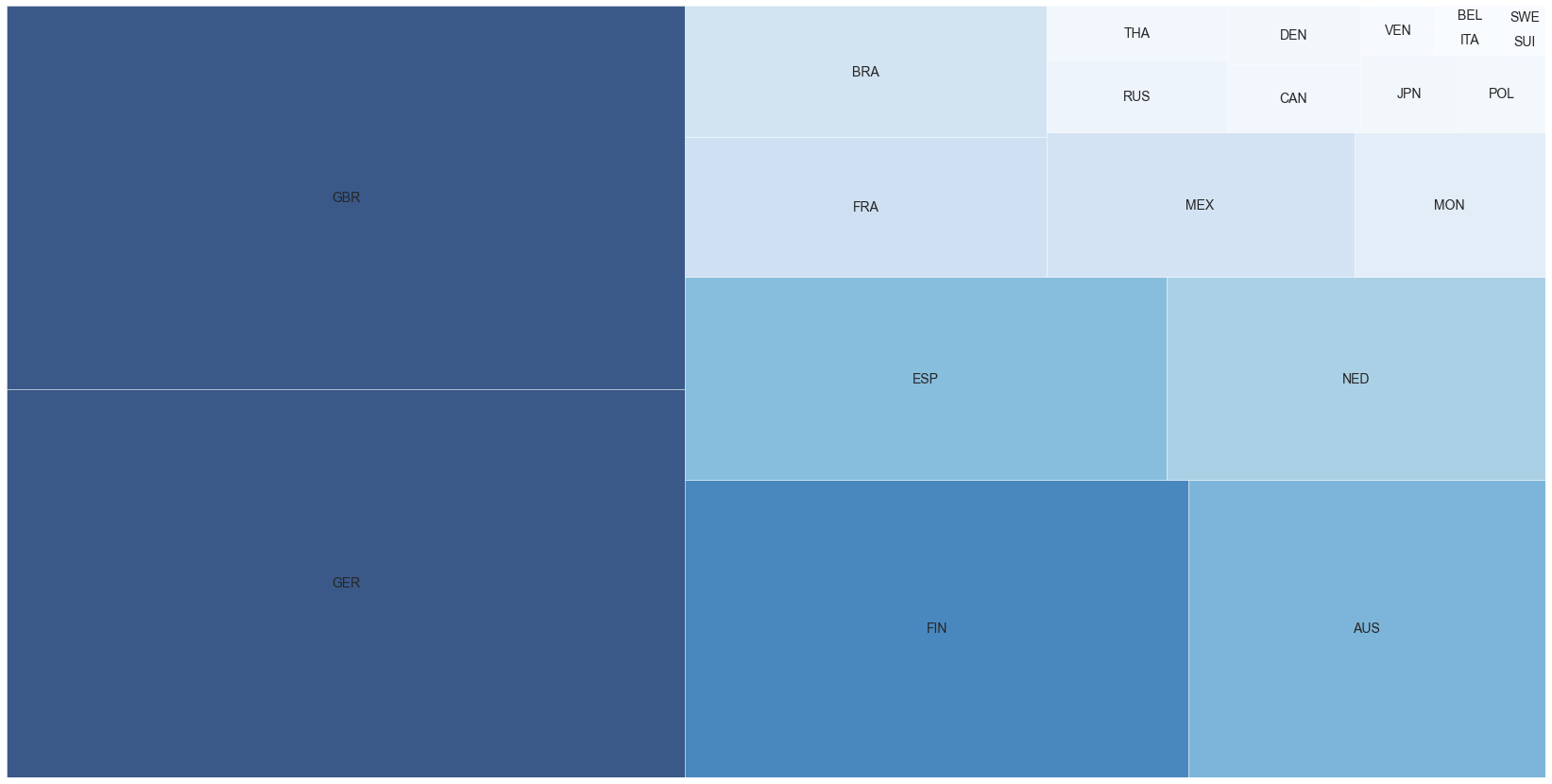
If the tree map makes you think GER (Germany) and GBR (Great Britain) are equal, here is a bar chart showing the actual points.
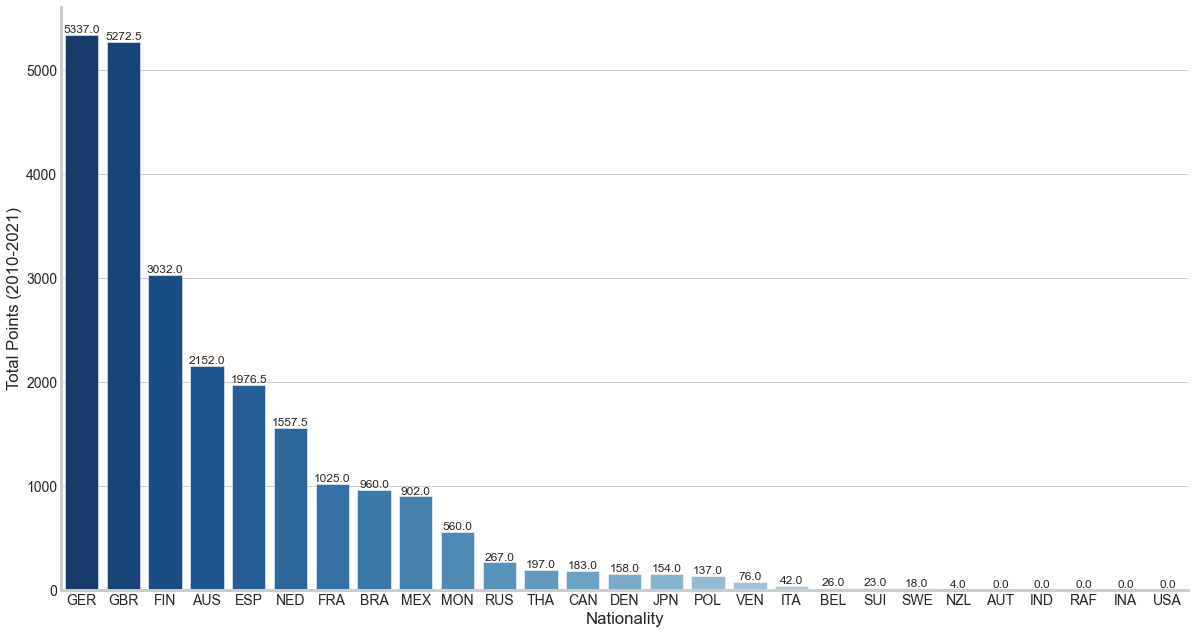
In all, 2021 was a fantastic year for Formula One. I wish the most crucial and deciding race had not ended in a controversial way. Sergio Perez played the best team-mate and tons of thanks to Lewis and Max for the entertainment.
Looking forward to more competition in 2022.
The data is from a Kaggle dataset revised with the last race results of 2021, and the plots were done using matplotlib, seaborn.