-
Updates in a Segment Tree →
In our previous post we saw Segment tree to compute binary associative operations on array ranges in an efficient manner. How do we go about updating elements and recomputing the max values, in an efficient manner?
Again, we know how to interpret our segment tree data structure (as a tree). We also know that the second half of our segment tree linear array contains the original array elements (leaf nodes). We make our update (change the value of an element) here first, and then bubble up the changes all the way to the root. We know that moving up the levels just involves looking for the pair-wise root nodes (at n for the pair (2n, 2n + 1)). This makes our implementation straight forward as shown below.
void STree::update(int index, int val) { index += n; st[index] = val; int new_val; while (index > 1) { index /= 2; new_val = std::max(st[index*2], st[index*2 + 1]); if (st[index] != new_val) st[index] = new_val; else return; } } -
Counting cokes faster for a different reward ... →
In our previous post we were wondering if we can count maximum number of coke cans dispensed from among a range faster than linear traversal of the array. We go back to our academic friend who taught us about Fenwick Tree for advice.
Our academic friend thinks this is a very easy problem. While Fenwick tree is a wonderful data structure, it can only compute reversible operations. He says there is a similar data structure called Segment Tree that can be used for any binary associative operation, besides cumulative operations as in Fenwick tree. He did not mention about Segment tree earlier as it occupies more space than a Fenwick tree. So, what is this Segment tree?
It is again a tree data structure, but we will work only with a linear array (just the interpretation is a tree). To construct a segment tree, we create an array twice the size of our original array. We then compute the max value of each pair of elements and store it in the location corresponding to the parent of the pair of elements. We already know that for any node n, the child nodes could be stored at 2n and 2n+1. So, in our array that is double the size of original array, all the elements towards the second half of the array would be the same as the original array (the child nodes) and they form the lowest layer of our tree interpretation (the leaf nodes). The pair-wise max form the next layer of nodes and so on until we converge on one root node that stores the max value in the array (the entire range). The following figure illustrates this:
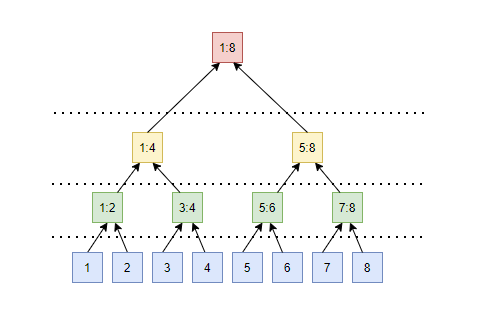
With this interpretation in mind, the construction of a segment tree is straight forward and it just involves tracking array indices to populate pair-wise max values.
STree::STree(std::vector<int> _arr) { n = _arr.size(); st.assign(2*n, 0); for (int i = n; i < 2*n; i++) st[i] = _arr[i - n]; for (int i = n-1; i > 0; i--) st[i] = std::max(st[2*i], st[2*i+1]); }Now, finding the max in a range would just involve looking at a few nodes rather than traversing all the elements in the range. For example, if we want to find the max value in the range 1 to 5, we just need to look at the values at the nodes labelled
1:4and5and compute the max among these two values, instead of looking at 5 values.int STree::rmq(int i, int j) { i += n; j += n; int max = INT_MIN; while (i < j) { if ((i & 1) == 1) { max = std::max(max, st[i]); i++; } if ((j & 1 == 1)) { j--; max = std::max(max, st[j]); } i /= 2; j /= 2; } return max; }But from past experience we also know that the values would need to be updated quite often. Can we also perform point updates as we did in our Fenwick tree - after all, this is another tree structure and we should be able to traverse it to make updates. We will see that in a future post.
-
Counting cokes for a different reward ... →
In a previous post we looked at the problem of counting coke cans dispensed for marketing rewards. Now, the new marketing manager is more detail oriented. He noticed that some shops have only one or a couple of coke vending machines while larger restaurants and offices have dozens of them. He wants to see which machine number dispenses the maximum number of coke cans from a range of machine numbers. And he has decided to index each establishment (restaurant or office complex) with just a single machine number. How would one go about computing the maxinum number of coke cans dispensed among a range of machines?
The solution, from our previous effort in solving a similar problem, is straight forward - we can maintain an array and compute the max value among a given range of indices.
int RMQ::rmq(int end) { int max = rarr[0]; for (int k = 0; k < end; k++) { max = std::max(max, rarr[k]); } return max; } int RMQ::rmq(int begin, int end) { int max = rarr[begin]; for (int k = begin; k < end; k++) { max = std::max(max, rarr[k]); } return max; }But what happens when we have millions of such queries - as different advertisers might be querying our database to send various kinds of offers? Do we have to traverse the range every time, in order to compute the max value? Or can we do better?
-
Sharing toys again →
In a previous post we saw how to compute the number if ways in which a bunch of toys can be rotated among as many number of kids without repetition. We also saw that we were computing intermediate problems over an over again, instead of remembering the computed value and reusing it (i.e. dynamic programming). Let us try it now.
We will first create a container to store and remember the results of intermediate computations as and when we perform them - in our case just a one dimensional array that stores how many ways we can distribute n toys among n kids. We can populate our container with the base cases (case of one kid and one toy and two kids and two toys).
int ways[n+1]; // base case ways[1] = 0; ways[2] = 1;Now, we iterate through the remaining number of toys, upto n and do the computation by reusing computed values instead of recursively calling the function to compute.
int ways_dp(int n) { int ways[n+1]; // base case ways[1] = 0; ways[2] = 1; for (int i = 3; i <= n; i++) ways[i] = (i-1) * (ways[i-1] + ways[i-2]); return ways[n]; }It is as simple as that.
-
Sharing toys happily →
Suppose you are incharge of a bunch of school kids and you have some expensive hi-tech toys, as many toys as the number of kids, from a sponsoring company that you are to ask the kids to share among themselves. The toys are all different and are sophisticated to different extent. You want each kid to have the toy for a day to play with. And you want to make sure no kid gets the chance to play with the toy the second time. How many possible ways can the toys be distributed?
Let’s formalize it a little more. Suppose there are n kids - k_1, k_2, …, k_n and so n toys -
1, 2, ..., n. The first day is easy - you distribute toy i to kid k_i. From the second day, you need to make sure k_i does not get i again for the next n days. If k_1 gets toy2, the problem is now reduced to n-1 kids and n-1 toys - i.e. one has to compute the number of ways in which you can distribute the toys1, 3, ..., nto kids k_2, k_3, …, k_n. i.e. each kid gets the toy that they haven’t yet played with (n-1possibilities). There can be this possibility as well: k_1 gets some toy j and k_j gets toy1(essentially, k_1 and k_j have swapped their toys), then our problem is now reduced to n-2 kids and n-2 toys.We see that the computation of the two cases are identical - one with
n-1toys and the other withn-2toys. Another thing to note is that when k_1 is given toyjthe first day, for the second day, there aren-1possible ways to distributen-1toys to k_1, and so on. It is a recursive computation. The base case is when there are two kids and two toys (they just swap their toys the second day - so just one possible outcome), and when there are one kid and one toy (you just let the kid play with the one available toy for one day - so not much computation for second day and so second day has 0 possible outcomes).int ways_r(int n) { // base case if (n == 1 || n == 2) return n-1; return (n-1) * (ways_r(n - 1) + ways_r(n - 2)); }Since we are computing the intermediate (sub-problems) over and over again, we can remember the intermediate results and make it more efficient. Let’s see how to do it in a future post.