-
Personalized movies ... any takers? →

I got into this discussion over lunch when I heard about the Netflix series “Black Mirror” which allows the audience to choose among a set of possible story endings. This is an excellent development, in my view, in that it not only brings more suspense and interest or attention to the content, on the lighter side it would also prevent spoilers.
Ever since I heard about south Indian movies that had different climaxes (although to appease the fan base in different regions), I have always wondered why not have multiple possibilities for a movie climax and serve (stream) the appropriate one depending on the goal of the movie audience - i.e., if the goal is to just watch the movie and return home happy, one could have a happy ending, if the viewer is adventurous or an FPS gamer, one could have a violent or tragic ending, etc.
Now that we have personalization using big data analytics everywhere, it should be possible for a streaming service to identify the likes and dislikes of the audience based on previous perferences, reviews, age, likes, and the many similar features to identify the best climax for each specific viewer, besides providing the viewer the choice to choose from alternate climaxes. Of course, the cost is in the making of several different versions of a movie or TV series which in a way could be reduced using today’s CGI that only gets better over time. The upshot would be more viewership and more discussion centered around the various climaxes. Instead of viewers just watching the movie and rating them, each different climax of the same movie would get rated by different personalities. Such a service could also stream a movie ending in such a way as to cheer you up when you are dull or to pump you up when you are demotivated. Movies will never be the same again!
If such a personalization of streaming content were to happen who would lead the way? Would it be Amazon Fire TV who has the machine learning backend to make personalization happen, NetFlix who has the influence to get the producers to make several interesting versions of a movie or TV series or Apple TV service if Apple were to get its innovation crown back? What do you think?
-
New year, Privacy and Security →
Happy New year friends!
What a year 2018 has been for the topic of privacy and security - from the most loved social network scrambling for clues to save themselves to the other social network built by the world’s best engineers still couldn’t save their data, besides struggling to stay relevant. While Europe was quick to pass GDPR, many other countries even in the developed world are yet to catch up with such laws and regulations. 2018 was also the year that saw the surge in smart speakers and home automation - isn’t that ironic?
But this story is not about the past, but about the future. Many top technology and auto companies rushing to fulfill the promise of self-driving or autonomous vehicles. It will definitely become a reality, to some extent, in at least the parts of the world where the infrastructure supports it. But the notion of foolproof security for such a technology is far from being achieved. With smartphone apps like Facebook, WhatsApp and Google+ security issues, we have only scratched the surface of the malevolent intent that is possible. Once autonomous vehicles and other IoT devices reach critical mass, the security issues are only going to multiply manifold and the impact of security flaws can have disastrous consequences. Imagine a malicious attacker taking control of traffic lights that talk to cars or cars talking to other cars to negotiate who gets to cross an intersection, or a mass rapid transit system that reroutes itself or changes frequency of rides depending on real-time ridership information using neural network based predictions. Imagine the impact of such a thing gone wrong. With the current day deep learning algorithms themselves not being tractable (i.e. one can not reliably track the computation from input data to the prediction step by step as in symbolic AI) it is going to be more challenging to resolve a security issue even after having identified it. Apologies for being pessimistic - but one should see this as a challenge for computer architecture and computer security research - a great time to be working in any of these fields.
If you want a job for the next one year, learn web/mobile app development, if you need a job for the next five years, train yourself with deep learning skills, if you need a job for the rest of your life, start working on computer security.
An interesting short documentary I happened to watch recently:
-
Cost-efficient Water Connections →
Suppose you are the tech-savvy engineer recruited by Public Works Department in your rural county. The rural county has wonderful flora, fauna and a few environmentalists and ecologists have been recruited to take care of the environment. There are a few houses built to host these people. Since the settlement is very new, the county has asked you to design a efficient water connection map to bring water to these settlements from a water source at one corner of the area. There are known paths where these water pipelines could be laid in a way that will have minimal effect on the environment. And you have been entrusted with using some of these paths in such a way as to minimise the cost and at the same time make sure every house gets a water connection.
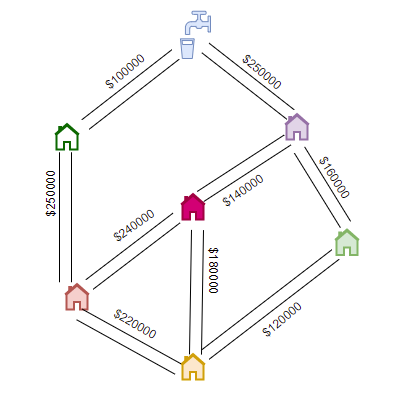
You sit down and think that the map is nothing but an implicit graph, the cost of laying the pipelines being the weights on the graph’s edges. The vertices are the houses. You have one special vertex which is the community’s source of water. Your plan is to find the path from the source of water to every house in the community. Further, there might be several such paths and you would have to choose the one that has the lowest cost. You recall algorithms for minimum spanning trees that you had learned in your algorithms lessons a decade ago and decide to give it a go.
Algorithmically, you have a set of edges with weights, a set of vertices and a special start vertex. Suppose each edge is defined by a source vertex
src, a destination vertexdestand the associated cost of laying the pipe between these verticescost- represented by the following structure:struct Edge { int src; int dest; int cost; };And our graph is defined by the total set of vertices
V(one source of water + the nodes representing houses) and a vector of EdgesEdgeListeach element is an Edge as defined above.Graph(int V, std::vector<Edge> edges)Assume that we also have a UnionFind data structure for us to use. Since we have to minimize the cost of construction, we try a greedy approach by picking the least expensive pipelines first - i.e., we sort
edgesin increasing order ofcost.std::sort(EdgeList.begin(), EdgeList.end(), [](Edge e1, Edge e2) { return e1.cost < e2.cost; });Once we pick the least cost edge, the next least cost edge may not be a neighbour of the current edge (i.e. having a common
srcordestvertex). In order to prevent cycles, we maintain a UnionFind data structure and keep adding the (minimum cost) edges we choose. As we collect the minimum cost edges, we can compute the cost using an accumulator.int Graph::kruskal_mst() { int V = size; UnionFind uf(V); std::sort(EdgeList.begin(), EdgeList.end(), [](Edge e1, Edge e2) { return e1.cost < e2.cost; }); int mst_cost = 0; int n = EdgeList.size(); for (int i = 0; i < n; i++) { Edge e = EdgeList[i]; // min cost edge if (!uf.isSameSet(e.src, e.dest)) { mst_cost += e.cost; uf.formUnion(e.src, e.dest); } } return mst_cost; }Finally, we will end up with the following minimum cost spanning tree, with pipelines laid with a total cost of
$990000.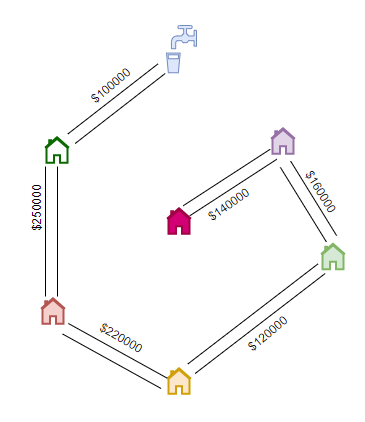
-
Pick the right courier ... →
Suppose you are a messenger boy making money by transporting packages from one office to another. Some packages like food need to be transported by a specific time (say lunch time) and certain others can get delayed but still have to be transported before the end of the day (by the time the other office closes). For each such job, you get paid a little. For certain packages, like cheques or gifts, you get paid a little more. So, you want to choose the jobs in such a way that you maximize your profit. You can’t refuse a job for reasons other than having another job to do at the same time. You want to write an algorithm to help you choose the right set of jobs.
As you are already greedy (or familiar with greedy algorithms), you can write one to solve this problem as well. This is just a variant of interval scheduling that we saw in our previous post. This case is commonly known as weighted interval scheduling as each interval (job) has a weight or value associated with it (profit) that we are trying to optimize for. In our case, our objective is to maximize the profit from doing jobs. And we want to identify the local decision rule that would also construct a globally optimal solution.
Assume we have jobs that are defined by the following:
struct Job { int id; int deadline; int profit; };Since we want to maximize our profit, we first sort the jobs in decreasing order of profits. Now your acceptable set of jobs could be as large as the set of jobs available (what if all the jobs provide the same profit - you may want to do all of them to maximize your profit). So, you have a set that is as large as the initial set of jobs.
// container for our final jobs (initialized to -1) // so that we would know if we filled in the slot already std::vector<int> sch_slot(n, -1); std::sort(jobs.begin(), jobs.end(), [] (Job const& j1, Job const& j2) {return j1.profit >= j2.profit; });Next, we try to delay the job as much as it is allowed by the deadline. If lunch delivery can wait until noon, you don’t want to take up that job and deliver it at 9 while sacrificing some other profit opportunity available at 9. So, we go through the list of jobs (ordered according to profits) that are not scheduled and schedule it while delaying the schedule as much as the job deadline allows. So, if lunch delivery can wait until noon, we would schedule lunch delivery the last slot before noon (say 11-12).
for (int i = 0; i < n; i++) { // delay the job as much as possible for (int j = jobs[i].deadline - 1; j >= 0; j--) { if (j < n && sch_slot[j] == -1) { sch_slot[j] = jobs[i].id; break; } } } -
Greedy algorithms vs Tik-Tok teenagers →
Suppose you are a famous celebrity getting several requests for interviews and appearances at events, of course with enough media presence, and you want to choose a few of the events so that you do not overcommit and keep your calendar relatively organized. You are relatively old fashioned and are having to compete against Tik-Tok teenagers for media clicks and so you want to accept as many invitations as possible so that it gives you maximum media coverage. The different events might be covered by different media outlets and so the more events you attend you get covered by more media outlets.
The point is, ladies and gentleman, that greed, for lack of a better word, is good. Greed is right, greed works. Greed clarifies, cuts through, and captures the essence of the evolutionary spirit. Greed, in all of its forms; greed for life, for money, for love, knowledge has marked the upward surge of mankind.
– Wall Street (1987)A greedy algorithm is one that creates a solution by making a local decision at each step with only local knowledge to optimize for some objective. In our case, our objective is to maximize the profit from doing jobs. And we want to identify the local decision rule that would also construct a globally optimal solution.
In our case, we want to accept as large a set of compatible invitations (invitations whose schedules do not conflict with one another) as possible. Your assistant provides you with the list of invitations and their schedules sufficiently in advance so that you can pick the ones that interest you. You start working out the possibilities in order to come up with the best algorithm.
The most obvious approach would be to accept the event that starts earliest, commit to it and pick other events depending on conflicts. But you see that you accepted such a thing, an event to clean a park, that consumed all of the day - just one event, and you declined four other events in order to do this.
You calendar actually looked something like this and you could have chosen the other events and had more media appearances.

So you think accepting events in order of their duration, preferring shortest events over longer ones, avoiding conflicts, is the right way to go. Your calendar from that boring Tuesday when you accepted a lunch invitation from a boring old actor makes you rethink the approach. Not just that you had to endure the boring actor or the lunch was not that great, you had to decline two other events, one of them a live music show and that sounds more fun now.
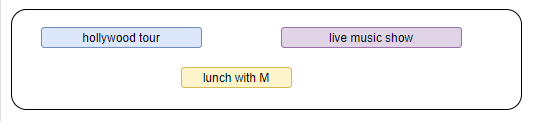
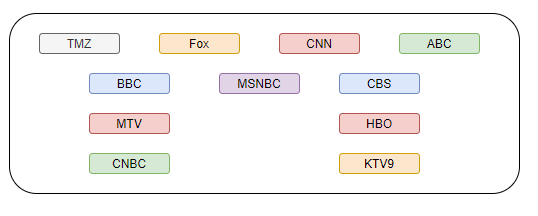
So, you decide not to go with prioritizing shortest events. The lunch meeting was too boring even if it was short. You decide to choose your events based on the least number of conflicts - if an event has less conflicts than others in your schedule, you want to prioritize that. That sounds promising. After your instagram post with you wearing a Bitcoin pendant went viral a couple of weeks ago, many tv channels wanted to interview you. And you committed to three of these interviews - BBC, MSNBC and CBS easily minimizing the conflicts in your calendar. Although the calendar looks confusing to choose the best set of events from, it was less confusing than the questions during those tv interviews or your answers to them.
You choose BBC because it conflicts only with TMZ and Fox (the other possible schedule) while choosing TMZ would conflict with BBC, MTV and CNBC (more conflicts). You picked the other events similarly - you choose the sequence of events in the second row - BBC, MSNBC and CBS as they seem to have minimal conflicts than the others. But now, putting the available options together, you see that you could have chosen four interviews (from first row) and had more media clicks.
Greedy algorithms are not very trivial. But they have been established for certain generic problems - commonly called interval scheduling that can be extended to many such real-world examples. A greedy rule that would lead to optimal pick of events is actually different from any of the choices above. The optimal choice is to pick the first request that finishes first (the idea being, you want to free up yourself as early as possible to get ready for the next event).
So, you sort the events of the day in increasing order of their finish times, pick the event that finishes first and among the rest of the events, pick the events that finish earlier and has no conflicts with already picked events.
Let us do it step by step, in a C++ program. Suppose you are given a list of events, each event described by its start and finish times.
struct Event { int start; int finish; };You first sort the given list of
nevents (std::vector<Event> events) according to increasing order of their finish times.std::sort(events.begin(), events.end(), [] (Event e1, Event e2) { return e1.finish < e2.finish; });Choose the first event that finishes. Let us assume we have a vector of events
schto collect our optimal schedule of events.sch.push_back(events[0])Now, you go through the rest of the events, check for conflicts and keep adding compatible events (events which do not conflict with the last selected event (
events[last_sel)) to your schedule.for (int i = 1; i < n; i++) { if (events[i].start >= events[last_sel].finish) sch.push_back(events[i]); }Armed with this algorithm, you can maximize the number of events you commit to, and get more media appearances.